销售预测的方法
销售预测是指利用数据和分析方法来预测未来一段时间内的销售情况。常见的销售预测方法包括:
时间序列分析:时间序列分析是基于历史数据进行分析,通过对历史数据的拟合来预测未来一段时间内的销售情况。时间序列分析常用的模型包括ARIMA、ARMA、ETS等。
- 优点:适用于单变量时间序列的预测,对于长期趋势、季节变动、周期性变化、随机波动等进行了建模,能够较好地预测未来的趋势和周期性变化。
- 缺点:对于非线性和复杂的关系难以建模,对于多变量问题无法处理,需要考虑平稳性和自相关性,需要预先确定时间窗口。
回归分析:回归分析是通过分析各种因素对销售量的影响程度来预测未来一段时间内的销售情况。回归分析常用的模型包括线性回归、多元回归、逻辑回归等。
- 优点:可以考虑多个变量之间的关系,可以使用线性或非线性回归模型进行预测,对于数据分布和噪声有一定的容忍度,易于理解和解释。
- 缺点:需要满足一些基本的假设,如线性相关性、同方差性、独立性等,如果数据存在异常值和离群点会影响预测效果,对于非线性关系需要进行特征工程。
人工神经网络:人工神经网络是一种类似于大脑神经网络的模型,通过输入历史数据,模型可以学习数据中的规律,并用于预测未来一段时间的销售情况。常用的人工神经网络模型包括BP神经网络、RBF神经网络、CNN神经网络等。
- 优点:可以处理非线性关系,适用于大量变量之间的复杂关系,对于多元时间序列数据预测效果较好,具有很好的泛化能力。
- 缺点:需要大量数据进行训练,训练时间较长,易于出现过拟合,需要对网络结构进行优化,同时需要处理数据的缺失值和异常值。
决策树:决策树是一种基于树形结构的预测模型,通过对历史数据进行分析和分类,将数据分成不同的类别,然后用树形结构来表示不同的分类结果。常用的决策树模型包括CART决策树、ID3决策树、C4.5决策树等。
- 优点:易于理解和解释,可以处理非线性关系,对于大量变量之间的关系建模效果较好,可以处理数据缺失和异常值。
- 缺点:容易出现过拟合,需要进行剪枝操作,对于数据噪声较大的情况效果不佳,对于连续变量需要进行离散化。
集成学习:集成学习是通过将多个模型的预测结果进行组合来得出最终的预测结果。常用的集成学习模型包括随机森林、AdaBoost、GBDT等。
- 优点:可以结合多个模型的预测结果,提高预测精度和鲁棒性,对于复杂关系和大量变量之间的关系建模效果较好。
- 缺点:需要训练多个模型,增加了计算量和训练时间,对于模型选择和集成方式需要进行优化,对于数据不平衡问题需要进行处理。
数据集要求
用于销售预测的数据集常常包含以下因素:
| 数据类别 | 变量 | 数值格式 | 解释 |
|---|---|---|---|
| 商品需求 | product_id | string | 商品编码 |
| date | string | 日期 | |
| is_sale_day | int | 是否促销 | |
| label | float | 商品销售量 | |
| 商品月订单 | product_id | string | 商品编码 |
| type | string | 商品类型 | |
| year | string | 年 | |
| month | string | 月 | |
| order | float | 商品月订单量 | |
| begin_stock | float | 商品月初库存 | |
| end stock | float | 商品月末库存 |
精确度指标
注意: 准确率评估需要区别于损失函数。
- 损失函数可以展现出预测值和真实值的偏离程度, 从而从侧面体现预测的准确性, 但损失函数的主要目的是为了帮助模型进行反向传播,达到模型训练的目的。
- 在销售预测中, 对于预测的准确性的定义相较其他领域更严格。可能只有预测值与真实值相同, 才为预测成功。也可能只需预测值只要与真实值的误差在一定范围内, 即为预测成功。而这个特点用均方误差和平均绝对误差无法分析出。因此在销售预测任务中, 需要重新定义精确度的评估指标,而不能用损失函数的来代替表示。
模型准确率评估可以使用一下方法:
计算每个月商品预测确率
、 、 , 其中 、 的计算公式和 一样! - 其中:
是商品i销量预测值, 是商品i销量真实值
- 其中:
计算累计所有预测月份的商品平均准确率:
损失函数
销售预测的损失函数通常采用: 均方误差(Mean Squared Error,MSE)或平均绝对误差(Mean Absolute Error,MAE)
- 均方误差和平均绝对误差都是衡量预测误差的常用指标,其中均方误差对异常值更加敏感,平均绝对误差对异常值的影响较小。在实际应用中,根据具体情况选择合适的损失函数。
均方误差
概念: 均方误差是预测值与真实值之差的平方和的平均值
公式为:
- 其中,
是预测值, 是真实值,n是样本数量。
平均绝对误差
概念: 平均绝对误差是预测值与真实值之差的绝对值的平均值
公式为:
- 其中,
是预测值, 是真实值,n是样本数量。
稀疏性
概念解释
- 稀疏性的概念:
稀疏性指的是,在大型模型中只有一小部分参数是有用的,而大部分参数都是无用的。因此,如果只考虑有用的参数,可以显著减少计算量,同时提高模型的泛化能力。 - 稀疏性的作用:
在机器学习和深度学习领域,通常会使用很大的模型来提高预测能力和准确性。然而,这些大型模型需要大量的计算资源,而且可能会过拟合,导致性能下降。为了解决这个问题,可以使用稀疏性来减少模型的计算是和复杂度。通过使用稀疏性,可以提高模型容量和能力,而不必成比例增加计算量。这样,可以减少模型的大小和训练时间,同时提高模型的泛化能力。因此,稀疏性是一种非常有效的技术,可用于构建大型、高效和准确的深度学习模型
使用稀疏性的示例
在自然语言处理中,通常采用自注意力机制 (self-attention mechanism) 来实现稀疏性。自注意力机制是一种基于注意力机制的神经网络结构,可以在不同位置之间建立关联,并学习到输入序列中不同位置之间的依赖关系
- 具体来说,自注意力机制将输入序列的每个元素作为查询、键和值进行处理,通过计算查询与键之间的相似度,得到一个权重分布,用于对值进行加权求和,得到该位置的输出表示.在计算相似度时,一般采用点积 (dot product) 或者其他类似于多层感知机(MLP) 的方法。
- 在自注意力机制中,为了实现疏性,通常会引入一种称为“掩码”(mask) 的机制。掩码可以用来屏蔽一些无关的输入,只保留与当前位置相关的输入,从而避免计算与无关输入之间的注意力权重。
- 通过这种方式,自注意力机制可以实现对输入序列的局部依赖关系建模,并且具有较好的可解释性和稀疏性,从而在自然语言处理等领域得到了广泛应用
稀疏注意力机制
概念解释
- 稀疏注意力机制的概念:
稀疏注意力机制(Sparse Attention) 是一种针对注意力机制中计算矩阵乘积的高效实现方式,可以有效减少计算复杂度,加快模型训练和推理速度。 - 稀疏注意力机制的原理:
- 在传统的注意力机制中,假设有n个输入序列,每个输入序列都有一个对应的 Query.Key、Value 短阵,用于计算与其他序列的关联度。传统的注意力机制会通过 Query 和 Key的矩阵乘积计算出每个 Query 与其他序列的关联度,然后通过 Value 矩阵的加权平均计算出最终的输出。但是,这种方式的计算复杂度为O(n^2),当输入序列数量很大时,计算开销就会变得非常高。
- 稀疏注意力机制通过限制计算矩阵乘积的范围,实现了高效的注意力计算。具体来说,稀疏注意力机制会为每个 Query 选择一部分 Key 进行计算,而不是计算全部 Key。这种方法可以有效减少计算矩阵乘积的复杂度,从而加速计算。
- 在自然语言处理领域,稀疏注意力机制通常被应用于 Transformer 模型中,用于处理非常长的文本序列。通过使用稀疏注意力机制,Transformer 可以高效地处理非常长的文本序列并且取得了在多项自然语言处理任务中的优异表现
具体实现方法
- 在稀疏注意力机制中,可以通过在计算注意力权重时使用稀疏矩阵来实现。具体来说,对于每个query,只有与之相关的一小部分key会被选择用于计算。这个过程可以通过将所有key表示为一个矩阵,将与每个query相关的key的位置用非零元素标记,其余位置用零填充,形成一个稀疏矩阵。
- 在计算注意力权重时,可以将query表示为一个向量,将key表示为一个矩阵,然后通过将query向是与稀疏矩阵相乘,得到一个向是,表示与该query相关的key的加权和。这个向是再通过softmax函数进行归一化,得到每个key的注意力权重。最后,将注意力权重乘以对应的value向量,得到最终的注意力表示。由于稀疏矩阵中只有一小部分元素是非零的,所以计算过程中只需要考虑这些非零元素,大大降低了计算复杂度。
信息利用率瓶颈问题
概念解释
信息利用率瓶颈问题 (lnformation bottleneck problem)是指在信息传输和处理中,由于信息量庞大、复杂度高等因素,导致信息的有效利用面临困难和限制。在机器学习中,信息利用率瓶颈问题通常指模型中存在信息丢失、冗余等情况,导致模型无法充分利用数据中的信息进行学习和预测。
实例说明
- 示例例举:
在自然语言处理任务中,对于一个句子,如果直接将其输入到模型中进行处理,模型需要处理大量的冗余和无用信息,而且难以捕捉到句子中的重要语义和关系。因此,需要使用一些技术和方法,例如注意力机制、稀疏表示等,来减少信息利用率瓶颈问题的影响,提高模型的性能和效率。 - 为什么会存在冗余或无用信息?
- 在自然语言处理任务中,一段文本通常会包含大量的冗余和无用信息,这些信息可能来自于一些停用词、无关词、标点符号等,这些信息并不对于任务有实际贡献,同时这些冗余信息还会占用模型的计算和存储资源,导致信息利用率瓶颈问题
- 在文本分类任务中,往往只需要关注文本中的一些重要信息,比如文本中的关键词.主语、谓语等,而并不需要关注一些无关紧要的词汇,如停用词、标点符号等。这些冗余信息会对模型的表现产生负面影响,并且会使得模型训练过程变得更加困难和耗时。因此,在处理文本数据时需要对文本进行预处理,从而去除几余和无用信息,提高信息利用率。
- 为什么使用稀疏注意力机制仍然会存在信息利用瓶颈?
虽然稀疏注意力机制能够显著减少计算量,但是仍然存在信息利用瓶颈问题。这是因为稀疏注意力机制中,每个Query只会选择一部分Key进行计算,而其他的Key并没有得到充分利用,导致信息的损失。另外,对于长序列来说,由于每个Query只能与一小部分的Key相互作用,因此无法捕捉到远距离的依赖关系,也会导致信息的丢失。因此,在实际应用中,需要通过一些方法来解决信息利用瓶颈问题,如引入多头注意力机制、自注意力机制等.
不可靠的时间依赖
- 直接从长期时间序列中发现时间依赖性是不可靠的

- 长期时间序列通常具有较高维度

- 时间延迟

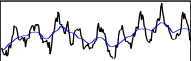
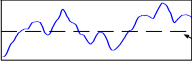
提取序列中的趋势信息
通过平均池化捕获趋势信息
- 补充说明:
因为在真实数据中,数据可能会存在许多细小的上下波动,但这些波动并不影响数据的整体变化趋势,因此在整体趋势信息中属于” 噪声 “。 通过均值池化得到的数据,即使每个数据之间有数值波动,但只要整体符合下降(上升)趋势,池化后得到的结果就表现为下降(上升) 趋势。因此可以使得数据更平滑,减少噪音的干扰,使得整体趋势更明显。
效果展示:
序列预测的模式
序列预测的模式分为:多模预测多模(multivariate predict multivariate)、多模预测单模(univariate predict univariate)、单模预测单模(multivariate predict univariate)
- 其他预测模式同理
输入序列、标签序列、预测序列
- 输入序列、标签序列、预测序列的关系
- 标签序列与预测序列的长度关系
标签序列和预测序列的长度不一定相同。在一些序列预测问题中,预测的序列长度可以是任意的,可能不同于标签序列的长度。例如,对于某个问题,我们可能需要根据过去一段时间的数据预测未来一个月的数据,那么标签序列长度可能为一个月,而预测序列长度可以自定。 - 为什么在训练时往往将标签序列设的比预测序列长
在训练时,标签序列比预测序列长,是为了使得模型能够更好地学习时间序列中的长期依赖关系,同时也能够更好地评估模型的预测性能。如果标签序列和预测序列长度相同,模型在训练过程中只需要记住前面几步的信息就可以预测后面的结果,而忽略了时间序列中长期的依赖关系。在标签序列比预测序列长的情况下,模型必须记住更长的历史信息才能进行预测,从而更好地捕捉时间序列的长期依赖关系,提高预测的准确性。
自相关(autocorrelation)
概念: 是指信号在不同时间点的取值之间的相关性,是一种描述信号自身变化规律的度量方式。在时域中,自相关函数(Autocorrelation Function,ACF)可以用来度量信号与自身在 不同时间点 的相关性。
即: 分析一段信号中一个点的值和其他点的值的相关性。
自相关函数可以用以下公式表示:
- 其中,
是信号的一个样本值, 是时间差的滞后步数, 表示期望。
自相关函数描述的是信号在不同时间点的取值之间的相关性,可以用于分析信号的周期性和频率成分。在信号处理和时间序列分析中,自相关函数是一种重要的工具。
- 当自相关函数的值随着时间差
的增加而减小,信号就越不相关。当自相关函数的值在某个时间差 处达到峰值,信号就具有一定的周期性或频率成分。 - 自相关函数不仅可以用于分析信号的性质,还可以用于信号的预测、滤波和谱分析等方面。
平稳化方法(stationarization)
概念: 平稳化方法是一种数据预处理技术,通常用于处理时间序列数据中的非平稳性。
目的: 是为了使数据的均值、方差和自协方差不随时间变化而保持稳定,以便更好地使用统计模型进行分析和预测。平稳化方法可以帮助去除非平稳性引入的噪声,提高时间序列预测的准确性
常用方法: 包括差分、对数变换、移动平均、指数平滑等。
常用方法简介
- 差分法
对于非平稳时间序列,可以通过对其一阶或高阶差分来消除非平稳性,使其变得平稳。一阶差分是指将每个时间点的观测值与前一个时间点的观测值之差作为新的观测值。高阶差分同理,可以迭代进行直到序列变得平稳为止。 - 移动平均法
对于非平稳时间序列,可以通过计算滑动窗口内数据的平均值来消除噪声和趋势,使其变得平稳。通常采用简单移动平均法或指数移动平均法。 - 分解法
对于非平稳时间序列,可以通过将其分解为趋势、季节性和随机成分三个部分然后分别处理每个部分来消除非平稳性。通常采用经验模态分解 (EMD)或小波分析等方法进行分解。
差分法
- 基本概念
差分是一种常见的去平稳化方法,可以消除时间序列数据中的非平稳性。 - 基本思想
将原始数据序列转化为其相邻时间点的差分序列,这样可以去除数据的整体趋势和季节性因素,从而得到一个平稳的时间序列。 - 适用场景
当一个时间序列数据存在明显的趋势或周期性变化时,它就是非平稳的。差分的过程就是对这种趋势或周期性变化进行消除的过程。通过计算相邻时间点之间的差值,可以消除原始数居序列中的整体趋势和季节性因素,从而得到一个平稳的时间序列。这种平稳的时间序列更容易分析和建模,因为它们没有非平稳性所带来的不确定性和复杂性。 - 差分间隔
差分间隔指的是相邻两个数据点之间的时间间隔,可以是天、小时、分钟等等。在时间序列分析中,差分间隔的选择通常要根据具体数据的特征和应用场景来确定。 - 常见问题
- 在差分中,通常取的是两个相邻数据之间的差值,即后一个数据减去前一个数据。因此,差分值可以是正数、负数或零,没有绝对值的概念。
- 如果原数据存在周期性,那么差分后的数据可能也会存在类似的周期性。这时候可以考虑使用季节性差分或者使用更复杂的模型来建模和预测。
- 季节性差分
- 季节性差分是一种特殊的差分方法,用于处理具有季节性的时间序列数据。其思路是将当前值与同一季节的上一年、上一个季度或上一个月的值进行差分,以消除季节性影响。
具体示例 假设我们有一个每月的时间序列数据,要进行季节性差分,就需要将当前月的值减去上一年同一月的值,得到一个新的序列。这样做可以消除季节性的影响,使得时间序列更趋于平稳,便于进行预测和分析。
- 季节性差分是一种特殊的差分方法,用于处理具有季节性的时间序列数据。其思路是将当前值与同一季节的上一年、上一个季度或上一个月的值进行差分,以消除季节性影响。
周期内变化&周期间变换
大部分时序数据都是由一种或多种周期不同的周期数据组合而成,呈现出多周期性;多种周期相互重叠并相互作用,使得建模变得棘手。因此在分析时序数据时, 常常通过傅里叶变换将原始数据中周期不同的数据分开, 从而降低分析难度。
- 周期内变化: 每个时间点数据受到周期内相邻点的影响而产生的变化, 用于表示周期内的短期时间模式。
- 周期间变化: 每个时间的数据受到其他相邻周期内数据的影响而参数的变化, 用于反映连续不同周期的长期趋势。

