传统Transformer
2017年,Google在论文 Attention is All you need 中提出了 Transformer 模型,其使用 Self-Attention 结构取代了在 NLP 任务中常用的 RNN 网络结构。相比 RNN 网络结构,其最大的优点是可以并行计算。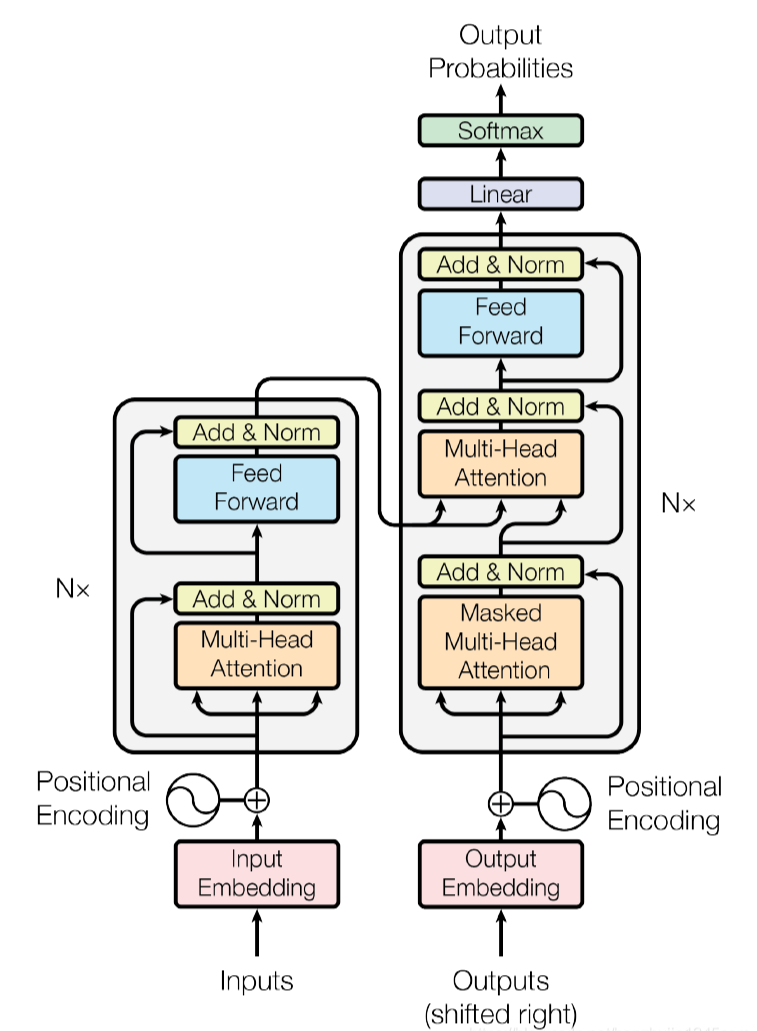
Transformer 本质上是一个 Encoder-Decoder 架构。因此中间部分的 Transformer 可以分为两个部分:编码器层和解码器层
注意力机制
一般注意力机制
自注意力机制
交叉注意力机制
多头注意力机制
多头自注意力机制
Feedforwaed层
子层连接结构
编码器层
每个编码器层都由结构如下的N个编码器组成: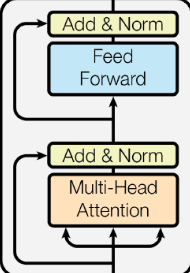
解码器层
每个解码器层都由结构如下的N个解码器组成: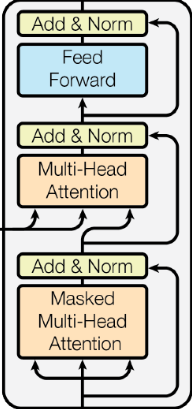
Auto-former
2021年,清华大学团队在论文Autoformer: Decomposition Transformers with Auto-Correlation for Long-Term Series Forecasting 中提出了 Autoformer 模型。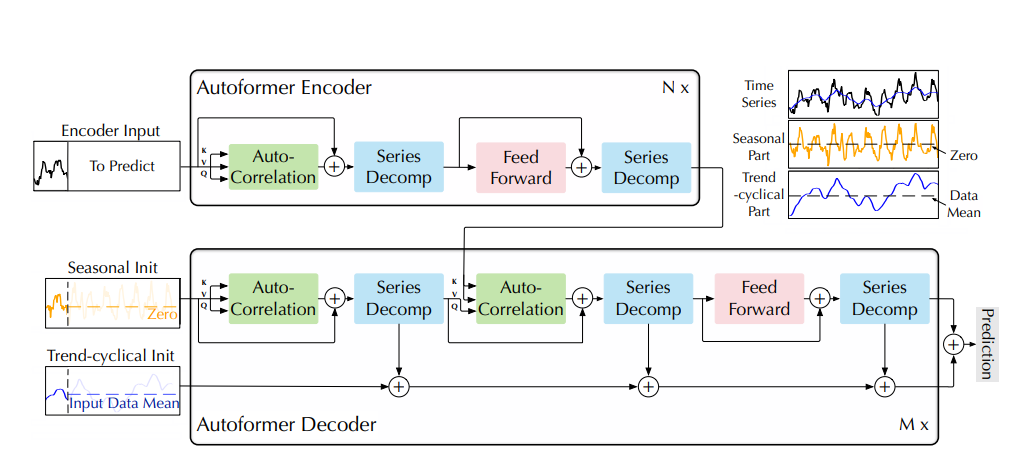
- AutoFormer延续了Transformer中Encoder-Decoder的框构。
- 保留了每层编码器层和译码器层中子层连接结构的个数
但是:- 将传统Transformer中的Hulti-HeadAttention(包括Masked Hulti-HeadAttention)替换成了新的Auto-Correlation
- 在每个子层连接结构后增加了一个Series Decomp层。
Auto-Correlation
- 通过快速傅里叶变换(FFT)处理Q和K
- 通过时延聚合(Time Delay Agg)完成注意力与V的融合
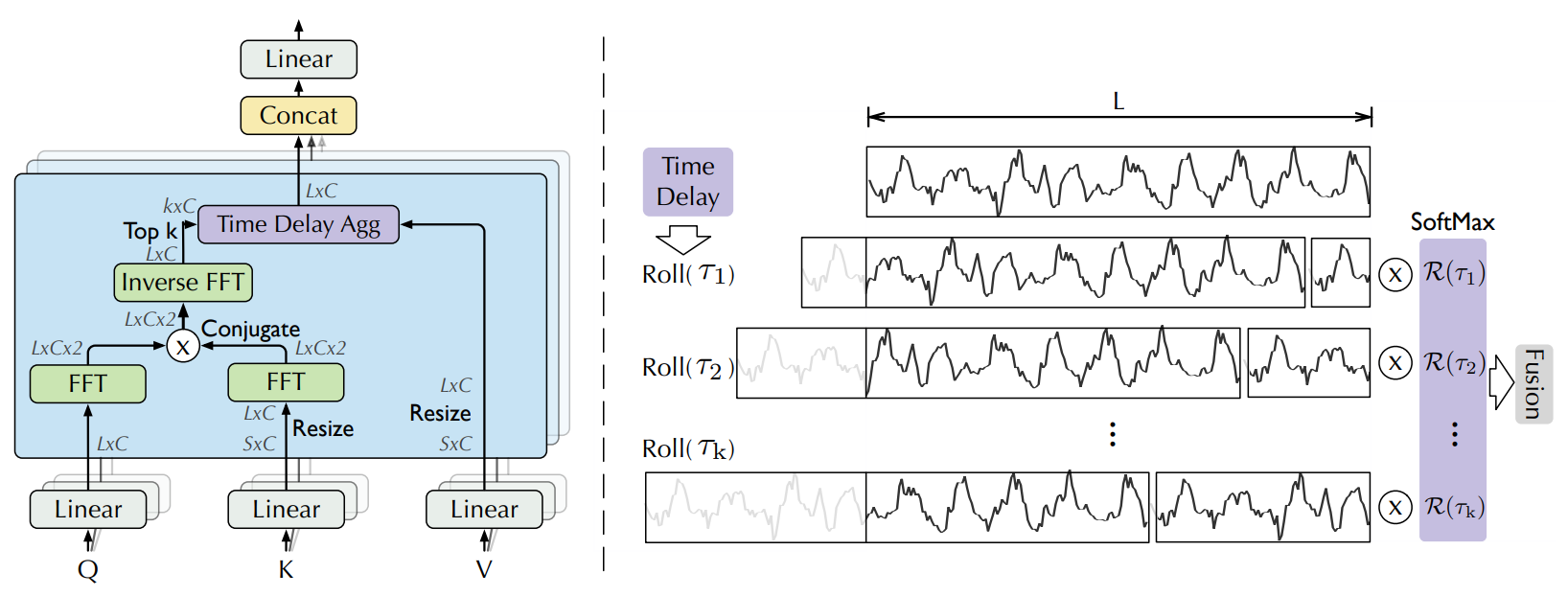
模块公式说明:
- 相关系数
- 定义用于提起Q,K相似度的相关系数
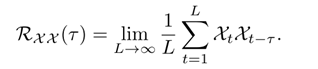
- 定义用于提起Q,K相似度的相关系数
- 模块实现的数学模型
- 选取相关系数最高的K个值
- 再用softmax对其进行标准化
- 最后通过实验聚合实现注意力
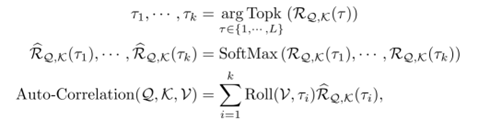
Series Decomp
- 主要原理
- 通过平均池化平滑数据, 提取数据的趋势信息
- 通过将原始数据减去趋势信息, 得到季节性数据
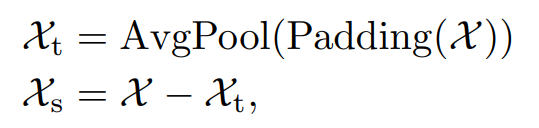
Non-stationary Transformers
2022年,清华大学团队在论文Non-stationary Transformers:Exploring the Stationarity in Time Series Forecasting 中提出了 Non-stationary Transformers 模型。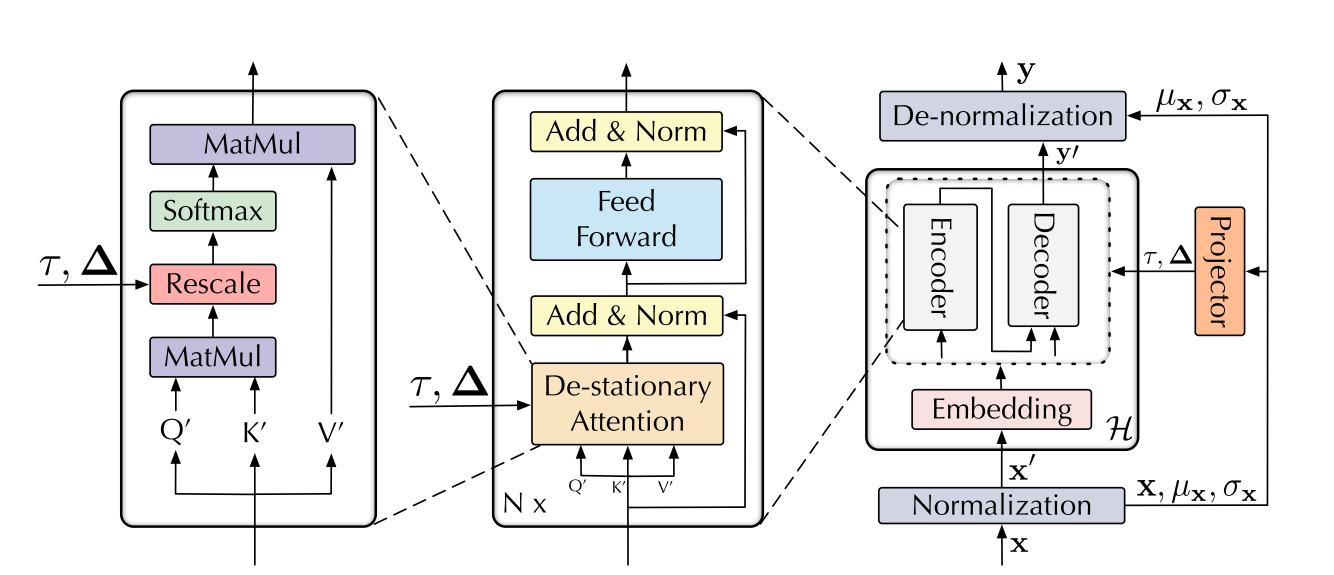
- 通过标准化模块(Normalization)平稳化获得平稳的input使时间序列数据更好预测,同时使用去平稳化模块(De-normalization)对output进行处理,恢复其周期性。
- 使用去平稳化注意力机制(De-stationary Attention)防止数据过平稳化,同时保留注意力机制的作用。
TimesNet
2022年,清华大学团队在论文TIMESNET: TEMPORAL 2D-VARIATION MODELING FOR GENERAL TIME SERIES ANALYSIS 中提出了 TimesNet 模型。

